Devin and the AI economy
So whats with this AI thing? Is it gonna replace my job as a software developer soon, or am I doomed to do this myself for a long time?
With the emergence of Devin from Cognition Labs, those questions seem to be more and more pressing. As technical staff we often develop a different viewpoint on things, especially if it directly matters to us.
This short essay is meant to explore the possibilities and shortcomings of “AIs” and technologies surrounding it from the perspective of a engineer, but for non-technical professionals.
Often times those are the people who enact real managerial change, which is why it is so important to accurately inform them on the current technical trends, without relying too much on the hype.
So what are those AIs anyways?
When we hear terms like AI and Machine Learning, we often get confused. GPT-3, DALL-E and Claude 2 are all generative AI models, meaning that they take raw data - say, all of Wikipedia or the collected works of Goethe - and “learn” to generate statistical probable outputs.
Generative models have been used for years prior in statistics to analyze numerical data. The rise of deep learning, however, made it possible to extend those capabilities to images, speech and other complex data types.
So no, in the current iteration, Generative AI cannot develop new capabilities beyond its reach or rather learned capabilities. While it can synthesize knowledge, and f.e write a paragraph of song lyrics in the style of Goethe, it only can mimic those styles and influences and not create its own.
Why Devin?
A few days ago, Devin got announced. With Cognition Labs slogan of building the first “AI Software Engineer” plenty of VCs got excited, and many developers got scared.
Devin can already pass Upwork Requests (which are usually reserved for Freelancers), it has an editor window where it can edit code, it has a browser window where it can interact with websites like GitHub, and it can read and make use of some documentation. The main thing seems to be the dedicated planning window and how it approaches tasks given in form. of prompts.
There is some legitimate question about just how cherry-picked these examples are, but there is not anything about what it does that seems infeasible. But it is not a real AI software engineer, its more another tool for us. Well why is that?
This is because employing software engineers (most of the times) means creating business value. The job of a software engineering team is generally to take those high-level business requirements from the non-programming business folks, turn those things into a product or service that can then be used by customers.
Even if Devin would write perfect code, he still is not a software engineer, and is not inteded to work with non-programmers to create value for customers.
What can Devin actually do?
Even if we now know, that conceptually, LLMs in our understanding will never fully replace software engineers, we still need to watch what LLMs can do, and how far they have already come. Looking at those graphs, Devin seems to be a major improvement to other LLMs.
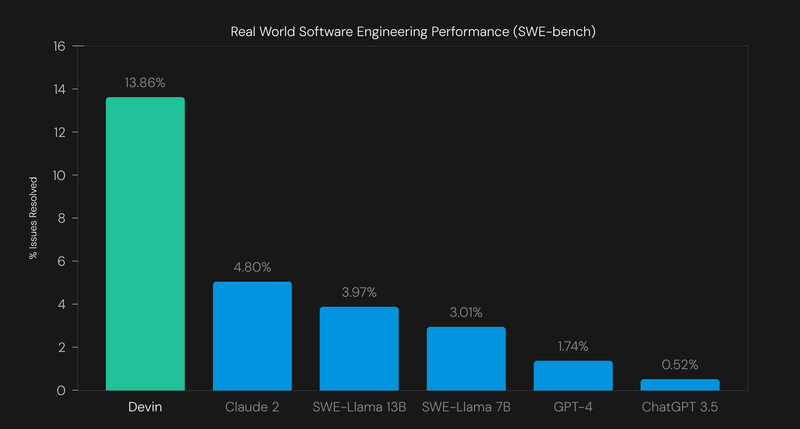
But what do those figures actually mean?
The SWE-Bench provides test queries from real world code issues (posted and resolved on Github) and tries to resolve them with the help of current models. The human score is in contrast 100 percent, because all of the problems are already solved. The “correctness” of the generated patches is assessed based on how well they pass the corresponding unit test.
The test results are divided into two categories: assisted and unassisted. So what are those questions like?
Lets look at some examples in the given json:
Latex parsing of fractions yields wrong expression due to missing brackets
Problematic latex expression: "\\frac{\\frac{a^3+b}{c}}{\\frac{1}{c^2}}"
is parsed to: ((a**3 + b)/c)/1/(c**2).
Expected is: ((a**3 + b)/c)/(1/(c**2)).
The missing brackets in the denominator result in a wrong expression.
The issue can be found here.
The following:
>>> n = Symbol('n', integer=True, even=True)
>>> (n**2/2).is_even
should return True, but it returns None (of course, this is also an enhancement).
That makes me think that perhaps symbolic integers should keep a more complex "assumptions" method, which generalizes "is_even" and "is_odd" to instead contain a dictionary of primes that are known to divide that integer, mapping to minimum and maximum known multiplicity.
I would like to think about it and post a proposition/plan, but I am not sure what is the correct github way of doing this.
The issue can be found here.
Even without having prior knowledge in the tech stack used, we can clearly see that the shown issues boil down into relatively simple failed/incomplete instructions to the code. Issues like that are usually not breaking, and can be resolved within a few minutes/hours, depending on the skill. So how many of those issues can the state of the art models train?
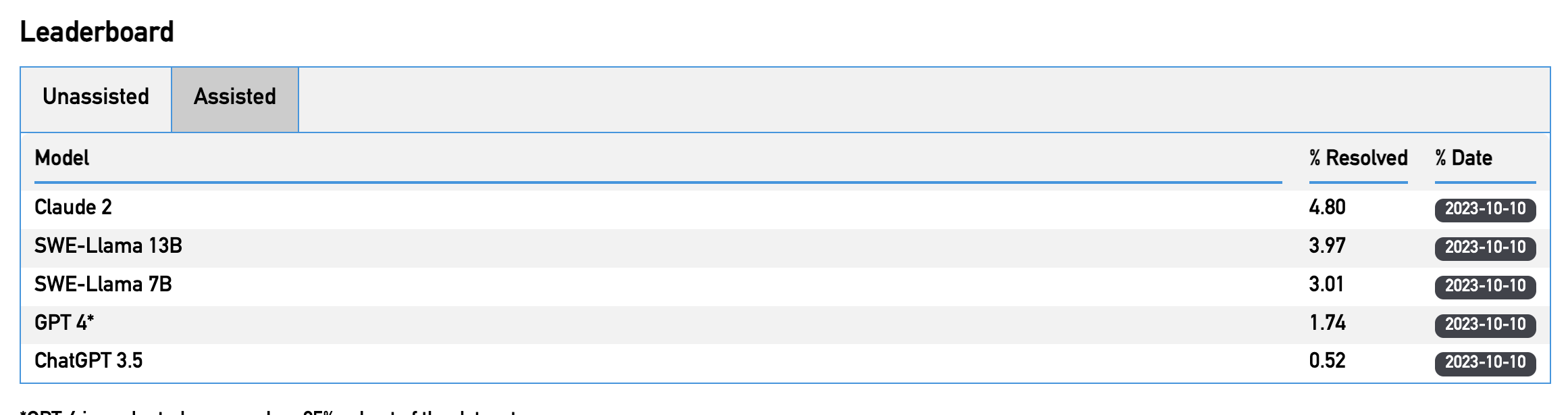
Looking at the current output, Claude 2 seems to be peaking at 4.8 %. This does not seem to be that threathening as one might assume, and I do not think that we should throw out software engineers for those kind of results. But there is one more thing. This is the “assisted” category. The tested systems get provided the list of files that were modified for that particular Issue. While human engineers often need to look up which files are contributing to the issue and then resolve said problem, this is not the case here at all. So what are the “unassisted” numbers?
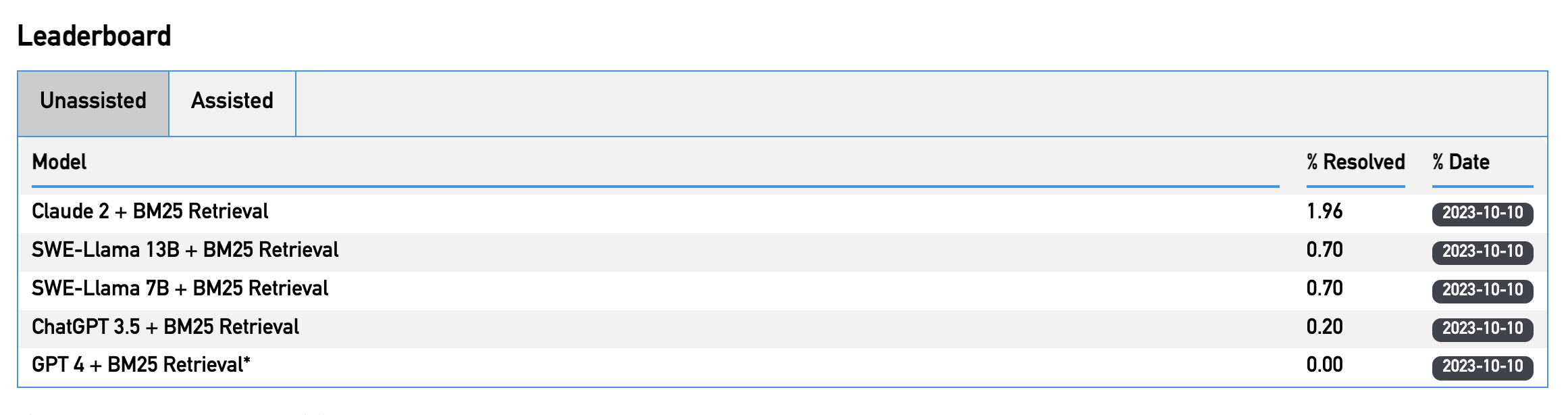
This looks pretty bleak for now. We see that most models currently cannot surpassed the one percent mark. So with Devin (which is trained on the same dataset), why did the numbers skyrocket? I cannot know for sure, but remember that they are plenty of factors and tactics to artificially mark up the percentages provided:
We currently do not know on which data subset the data was trained on.
The best yield achieved is probably the one shown.
Other models presented do not have the mentioned environment (cli, reusability of code fragments etc.) available, which is probably why the results are so different.
The goal here is not to have the most correct assessment of technical prowess, but to cater to VCs and sell the product - which is totally understandable.
But maybe you are still not convinced, because you have seen headlines similar to that one?

Seems scary, right? Did we make so much progress in one year? Was Claude not able to resolve algebra, but now we have truly build a near perfect AI?
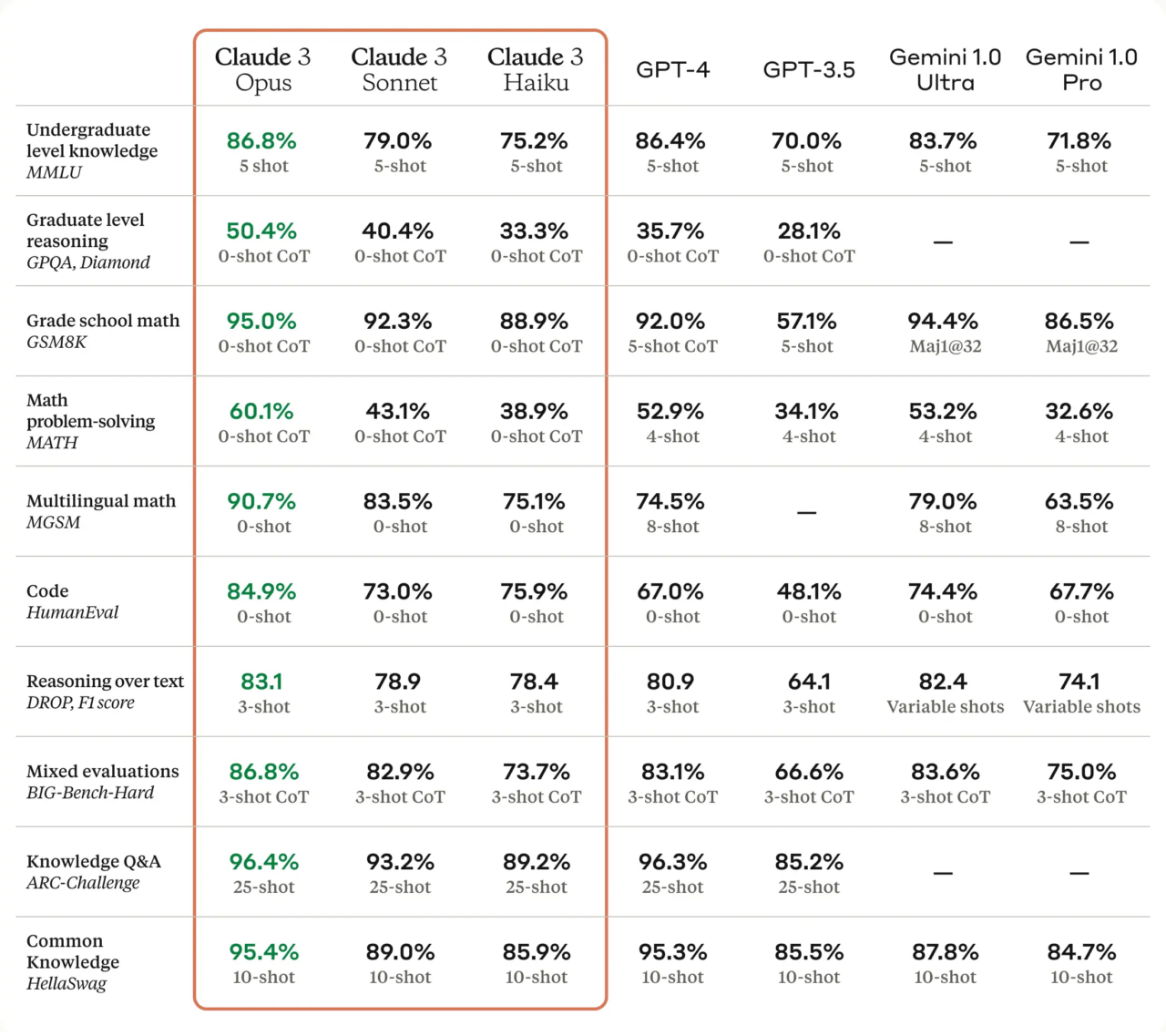
Oh wow, the numbers seem to be exponentially higher than before? Why is that? First of all, the test environment uses a different benchmark, including HumanEval. Using their dataset, we can extract the questions used for the test.
You are given a non-empty list of positive integers. Return the greatest integer that is greater than
zero, and has a frequency greater than or equal to the value of the integer itself.
The frequency of an integer is the number of times it appears in the list.
If no such a value exist, return -1.
Examples:
search([4, 1, 2, 2, 3, 1]) == 2
search([1, 2, 2, 3, 3, 3, 4, 4, 4]) == 3
search([5, 5, 4, 4, 4]) == -1
If you want to see the output for yourself, you can use the terminal and search the question for yourself curl -L -q -s https://github.com/openai/human-eval/raw/master/data/HumanEval.jsonl.gz | gzip -cd |\ jq -sr '([ .[].test | length ] | max) as $m | map(select (.test | length == $m))[0] | "\n\(.task_id)\n \(.prompt)"'.
For everybody who has some basic experience of coding at all, this question seems rather lacking in itself. It could be used in technical interview to scrape the basic understanding of a graduate CS student without any online help. This question does not hold any real value in production environments, and is specifically designed to be understood by LLMs, because of its innate simplicity and trainability.
If you do not believe me, you can try it out yourself. The other examples in itself meet the same threshold of complexity. It is not surprising, that the models tested on that benchmark thus achieve such high scores.
So is it all just hype?
No. But it should be regarded as a bubble. And like every bubble, it will burst at some point. LLMs are extremely valuable for future software engineers and technical staff as a tool to automate things and be more productive. It is not going to replace us in the near future when it comes to solving coding problems though, and I do not think it will ever replace the term “software engineer” conceptually.
What is important though is to get aquainted in those tools and look for possibilities on how to efficiently use “AI” to leverage your value as a professional. For non-technical people it is more important than ever to listen to technical professional on what to expect in the current changes, and how to adapt, without buying to much into the hype that is circulating social media. If you as a new programmer think that writing code is the main part of your job or should be the focus on what you do - be ready for big changes and extend your skills into other areas of software engineering.
Nonetheless - be critical, adapt to a new upcoming environment and do not forget to be relaxed - Devin is not gonna take your job tomorrow. :D